こんにちはSREチームの宮後(@miya10kei)です。最近、デスクシェルフを買ってからデスク周りがとてもスッキリして大満足しています😏
前回に続いて非同期タスク関連の取り組みを紹介します!
ところで、、、障害が発生したときの調査って大変ですよね?非同期で実行される処理なんかは特に原因の特定が難しいと思っています💦
そこで、今回は障害時の調査用に非同期タスクの実行パラメータを永続化し、Athenaから検索できるようにした仕組みを紹介します。
背景
前回紹介した「非同期タスクのメトリクス収集術」で非同期タスクの状態を確認できるようになりました。しかし、障害時にどんなパラメータで実行されたのかといった詳細な情報まではまだ把握できません。エラーログにしっかりと必要な情報を出力できていれば良いのですが、なかなかそうはなっていないのが現状です、、、。
また、実行パラメータには場合によっては個人情報が含まれるケースがあるため、全員が閲覧できる場所においそれと出力することもできません。出力して良いものと悪いものを精査するのにも非常に時間がかかります。
そこで、今回はすべての非同期タスクの実行パラメータを通常のログ出力先とは別の場所に永続化し、特定の人だけが検索できるようにすることで障害調査の容易性とセキュリティのバランスを取ることにしました。
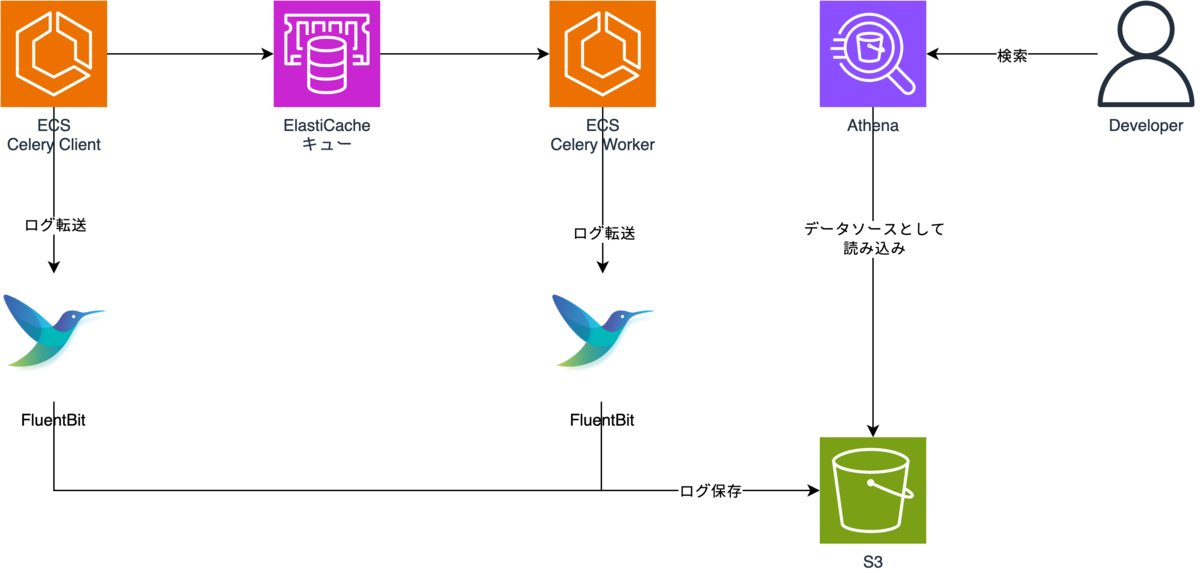
全体構成
Park Directでは通常のアプリケーションログはFluent BitでDatadogに転送し、開発者なら誰でも検索できるようになっています。
しかし、今回は以下の課題があったため、S3に永続化しAthenaから検索する構成としました。
- 実行パラメータログには個人情報が含まれるケースがある
- Datadogには個人情報を転送しない方針となっている
- 現状、ログ種別毎に閲覧者のアクセス制限をかける運用になっていないため
- パラメータログは大量に出力されるため、Datadogに転送するとコストがかかりすぎてしまう
DatadogとS3のどちらにログを転送するかはFluent Bitで振り分けるようにしています。
また、非同期タスクをキューに登録できなかった場合や、実行パラメータログと併せて処理結果も出力したいという事情なども考慮し、Celery ClientとWorkerの両方で実行パラメータログを出力するようにしました。
実現方法
それでは、具体的な実現方法を紹介していきます。今回はアプリケーション、Fluent Bit、S3、Athenaと複数の箇所に手をいれているため順番に説明していきます。
アプリケーションの実装
Celery Client側の実装
Celery Client側では以下の項目を実行パラメータログとして出力しています。
| 項目 | 説明 |
|---|---|
| time | 出力時刻 |
| type | Celery Clientのログであることを表す識別子 |
| module | タスク名 |
| params | タスクに渡されるパラメータ |
| tasks_id | Celeryが払い出すタスクのID |
実装は以下になります。すべての非同期タスク登録時に実行パラメータログを出力するため、celery.app.task.Taskのapply_asyncを拡張することで実現しました。
import json import logging from datetime import datetime import pytz from celery import Celery, Task _logger_client = logging.getLogger("celery_param_log_client") class CustomTask(Task): def apply_async(self, *args, **kwargs): result = None try: result = super().apply_async(*args, **kwargs) finally: task_json = { "time": f"{datetime.now(pytz.timezone('Asia/Tokyo')).strftime('%Y-%m-%d %H:%M:%S.%f')}", "type": "client", "module": f"{self.__module__}.{self.__name__}", "params": {"args": f"{args}", "kwargs": f"{kwargs}"}, "task_id": f"{result}", } _logger_client.info(json.dumps(task_json)) return result app = Celery("Task") app.Task = CustomTask # --- hello.apply_aync()
Celery Worker側の実装
Celery Worker側では以下の項目を実行パラメータログとして出力しています。
| 項目 | 説明 |
|---|---|
| time | 出力時刻 |
| type | Celery Workerのログであることを表す識別子 |
| module | タスク名 |
| params | タスクに渡されるパラメータ |
| tasks_id | Celeryが払い出すタスクのID |
| result | 処理結果 |
実装は以下になります。すべての非同期タスク処理で共通の処理をおこないたいため、デコレータで実現しました。
import json import logging from datetime import datetime from functools import wraps import pytz def task_execution_log(func): @wraps(func) def wrapper(*args, **kwargs): task_request = current_task.request has_error = False try: response = func(*args, **kwargs) _logger.info(response) except Exception as e: has_error = True raise e finally: task_json = { "time": f"{datetime.now(pytz.timezone('Asia/Tokyo')).strftime('%Y-%m-%d %H:%M:%S.%f')}", "type": "worker", "task_id": f"{task_request.id}", "module": f"{task_request.task}", "result": "N/A", "params": {"args": f"{args}", "kwargs": f"{kwargs}"}, } if has_error: task_json["result"] = "Failure" else: task_json["result"] = "Success" _logger_worker.info(json.dumps(task_json)) return response return wrapper # --- @task_execution_log def hello():
Fluent Bitの設定
Fluent Bitを以下のように設定することで実行パラメータログのみをS3に転送するようにしています。(実行パラメータログに関わる部分のみを抜粋しています)
# FireLenseの仕様で16KB以上のログは複数行に分割されるため、マルチライン処理をおこなう
[FILTER]
name multiline
match *
multiline.key_content log
mode partial_message
# CeleryClientから出力されるClientパラメータログのタグをcelery-param-log-clientに変更
[FILTER]
Name rewrite_tag
Match client-firelens-*
Rule log (^.*\"type\":\s\"client\".*$) celery-param-log-client false
# CeleryWorkerから出力されるWorkerパラメータログのタグをcelery-param-log-workerに変更
[FILTER]
Name rewrite_tag
Match worker-firelens-*
Rule log (^.*\"type\":\s\"worker\".*$) celery-param-log-worker false
# celery-param-log-clientとcelery-param-log-workerタグのログをS3に転送
[OUTPUT]
Name s3
Match celery-param-log-*
region ap-northeast-1
bucket ${バケット名}
s3_key_format /$TAG[0]/year=%Y/month=%m/day=%d/%H%M%S-$UUID.gz
upload_timeout 1m
compression gzip
use_put_object On
S3の設定
前述の設定でS3には実行パラメータログが以下の構成で保存されます。
バケット名
├── celery-param-log-client
│ └──year=yyyy
│ └──month=MM
│ └──day=dd
│ ├──HHmmSS-xxxxxx.gz
│ ├──HHmmSS-xxxxxx.gz
│ └──HHmmSS-xxxxxx.gz
└── celery-param-log-worker
└──year=yyyy
└──month=MM
└──day=dd
├──HHmmSS-xxxxxx.gz
├──HHmmSS-xxxxxx.gz
└──HHmmSS-xxxxxx.gz
本バケットの閲覧者を制限する必要があるため、S3バケットに以下のポリシーを設定しています。
{ "Version": "2008-10-17", "Statement": [ { "Effect": "Deny", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::{バケット名}", "arn:aws:s3:::{バケット名}/*" ], "Condition": { "ArnNotLike": { "aws:PrincipalArn": [ "arn:aws:iam::*:role/aws-reserved/sso.amazonaws.com/*/AWSReservedSSO_{ロール名}_*" ] } } } ] }
Athenaの設定
AthenaからS3内のデータを検索できるようにするために以下のDDLでテーブルを作成します。また、パーティションを自動読み込みするためにyear/month/dayに対してPartition Projectionを設定しています。(以下はCeleryWorker側の例です)
CREATE EXTERNAL TABLE `worker_log`( `time` timestamp COMMENT 'from deserializer', `type` string COMMENT 'from deserializer', `task_id` string COMMENT 'from deserializer', `module` string COMMENT 'from deserializer', `result` string COMMENT 'from deserializer', `params` struct<args:string,kwargs:string> COMMENT 'from deserializer', `source` string COMMENT 'from deserializer', `container_id` string COMMENT 'from deserializer', `container_name` string COMMENT 'from deserializer', `ecs_cluster` string COMMENT 'from deserializer', `ecs_task_arn` string COMMENT 'from deserializer', `ecs_task_definition` string COMMENT 'from deserializer') PARTITIONED BY ( `year` string, `month` string, `day` string) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat' LOCATION 's3://{バケット名}/celery-param-log-worker' TBLPROPERTIES ( 'classification'='json', 'projection.day.digits'='2', 'projection.day.range'='1,31', 'projection.day.type'='integer', 'projection.enabled'='true', 'projection.month.digits'='2', 'projection.month.range'='1,12', 'projection.month.type'='integer', 'projection.year.format'='yyyy', 'projection.year.interval'='1', 'projection.year.interval.unit'='YEARS', 'projection.year.range'='NOW-31DAYS,NOW+9HOUR', 'projection.year.type'='date', 'storage.location.template'='s3://{バケット名}/celery-param-log-worker/year=${year}/month=${month}/day=${day}/', )
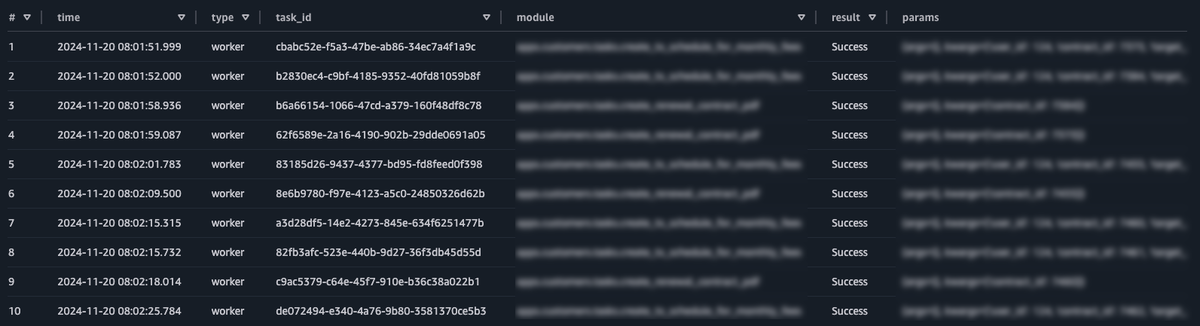
ここまで実施することでA、thenaで次のSQLを発行することで、非同期タスクに渡された実行パラメータを確認することできるようになりました🎉🎉🎉
SELECT * FROM worker_log WHERE year = '2024' AND month = '11' AND day = '19'
Tips: 非同期タスクのロストに対する監視
Athenaから実行パラメータログを検索できるようにしたことで、障害時の調査が容易におこなえるようになりました。一方で、もう一つ別の恩恵があったのでTipsとして紹介します。
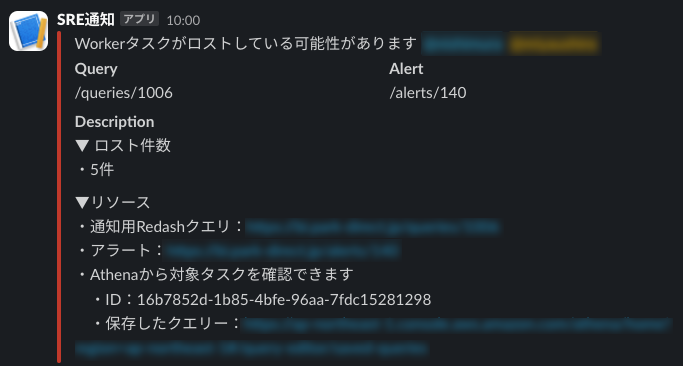
Park Directでは大量の非同期タスクを日々捌いているのですが、ある時、一部の非同期タスクが処理されないままロストしているのではないか?という疑惑が生じました。
そんなとき、CeleryClientとCeleryWorkerの両方で実行パラメータログを取得していたことが功を奏し、Athenaから次のSQLを発行することでロストしたであろう非同期タスクの件数を把握することができました。
WITH current_jst AS ( SELECT current_timestamp AT TIME ZONE 'Asia/Tokyo' - INTERVAL '1' DAY AS jst_timestamp ) SELECT count(1) AS lost_count FROM client_logd c WHERE time IS NOT NULL AND (c.year, c.month, c.day) = ( SELECT CAST(EXTRACT(YEAR FROM jst_timestamp) AS varchar), LPAD(CAST(EXTRACT(MONTH FROM jst_timestamp) AS varchar), 2, '0'), LPAD(CAST(EXTRACT(DAY FROM jst_timestamp) AS varchar), 2, '0') FROM current_jst ) AND NOT EXISTS ( SELECT 1 FROM worker_log w WHERE c.task_id = w.task_id );
弊社ではBIツールとしてRedashを使用しており、データソースとしてAthenaに指定することができます。Redashアラートとして上記SQLを定期実行しSlack通知することで、非同期タスクのロストに対して監視をおこなっています。
さいごに
今回は非同期タスクの実行パラメータログをAthenaから検索するための仕組みを紹介しました。
非同期タスクはスケーラビリティ向上やリソースを効率的に利用できるという面でメリットがありますが、その反面、障害時の調査が難しいというデメリットがあると思っています。
実行パラメータを永続化し、検索できるようにするだけで障害調査やリカバリー対応が格段に実施しやすくなります。
もし、同じことで困っている方がいたら、ぜひ参考にしてみてください!!!