@2357giです。Pixel7aを買った次の日にPixel8aが発表されて悲しいです。
先日EC2で長らく動いていたRedashをECSに載せ替える作業を行ったのですが、データ量が大きいクエリを実行するとタイムアウトしてしまう問題が発生しました。 (大きいクエリとは具体的には50万行ほど結果が返ってくるクエリなどです。160MBくらいです😇 )
結論としては、EC2からECSへ移行した際に nginx を外してしまったのが原因でした。
ALB - ECS 構成なので、nginxは要らないよね〜といつも通りのクラウドネイティブ化作業をした結果、gzip圧縮されていないレスポンスを返してしまい、タイムアウトが発生していました。
最終的にgzip圧縮を行う設定を書いたnginxを挟むことにより無事解決することができたのですが、Redashというアプリケーションの性質やECS化のタイミングが重なり、ちょっと調査に手こずったのでその辺りを書いていけたらなと思います。
あらすじ
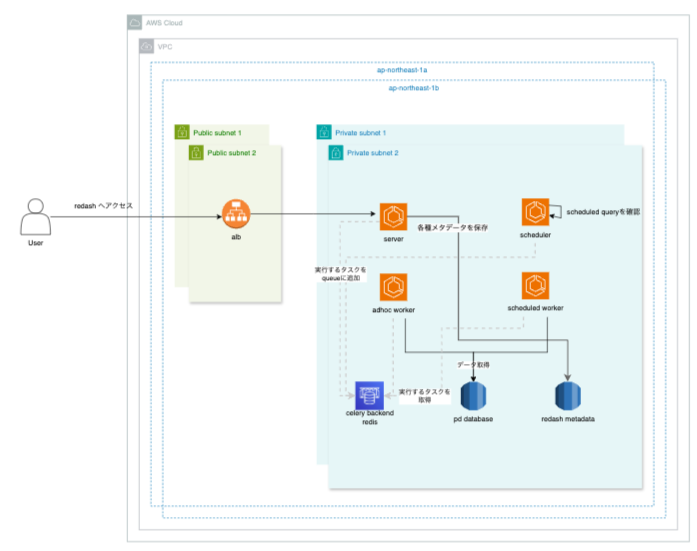
ニーリーではBIツールとしてRedashがあらゆる部署で使われており、サービスを運用する上で欠かせないものになっています。ですが、EC2上で長く塩漬けにされたRedashは安定性に不安なところがあり、またEC2自体をちゃんと管理していくコストも大きかったので、ECS へ移行することにしました。
EC2の場合は1つのインスタンスにserverやscheduler, worker各種が乗っかっていたので、クエリが大量に発行された際にworker単体でスケーリングを行うといったこと難しい状態でもありました。そこで、ECS化に伴いworkerの単体スケーリング実現もスコープに含めることとしました。
移行方法
ParkDirectではクラウドリソースの管理にTerraformを用いており、例の如くRedash用のECSもTerraformで管理することにしました。
従来は単体のEC2の中にRedashの各種リソースである server, scheduler, adhoc worker, scheduled worker が同居していました。
workerは2種類存在し、スケジューリングされたクエリを実行するのがscheduled worker、 画面上から実行されたクエリを実行するのがadhoc workerとなります。
前述した通り、adhoc workerだけスケーリングを行いたいので各種リソース毎にECS serviceを分けて定義しました。
Redashは /status.json というエンドポイントを叩くことによりqueueのサイズなどを取得することができます。
EC2時代からRedashのモニタリングとして、1分毎に該当のエンドポイントを叩き、Datadogへメトリクスとして登録するLambdaが存在しました。
そこで、このLambdaを改良しCloudWatch Metricsにも同様の値を送信するように変更し、その値を元に adhoc worker のタスク数をオートスケーリングするように修正しました。
これにより、大量のタスクや重いタスクが実行されキューが貯まった際にworkerがオートスケールして、幸せになれるはずでした。
はずでした......。
移行後に発覚した問題点
いくつかのクエリが正常に動作することを確認し、workerがオートスケールすることも確認を行った上でEC2からECSに移行を行いました。
移行作業自体も問題なく行われたのですが、少しずつ「タイムアウトのエラーが増えるようになった」といった問題が出はじめ、調査を実施しました。
確かにサイズの大きいRedash querieを実行すると処理時間が掛かり、且つものによってはタイムアウトが発生していました。

RedashのECS リソースのチューニングを行っていなかった為、workerのスペックチューニングを実施しました。しかし、依然として改善しませんでした。
また、Redashの管理画面 ( /admin/queries/tasks )で実行中のクエリを監視したところすでに処理が終わっている状態だったので、worker側の問題ではないと判断しました。
その後、調査メンバーの中で回線速度によってタイムアウトする人としない人がいる、そもそもpayloadがデカいといった点からレスポンスがgzip圧縮されていないことを発見しました。結論として、冒頭にも記載した通りクラウドネイティブ化に伴いnginxを取り外していたため該当事象が発生していました。
最終的に、gzip圧縮オプションを有効にしたnginxを挟み、無事解決することができました。
終わりに
ALBを使う上でどのような場合だとnginxが必要なのかといった視点や、タイムアウトした場合クライアントからクラウドインフラまで全ての箇所が原因となり得るという視点がおろそかになってしまっていたことを反省する良い機会でした。